一、CPU 使用率是怎么计算的
Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。比如在我的系统中,节拍率设置成了 1000,也就是每秒钟触发 1000 次时间中断。
$ grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=1000同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。
为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
所以理论上的 CPU 使用率计算方式为:
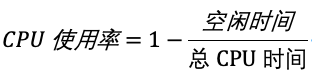
但事实上,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,所以 CPU 使用率的实际计算方法为:

所以对 CPU 使用率进行分析时,需要注意:性能分析工具的间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。比如,对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。
二、如何查看 CPU 使用率
top 和 ps 是最常用的性能分析工具:
top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
ps 则只显示了每个进程的资源使用情况。
1)top
top 的输出格式为:
# 默认每3秒刷新一次
$ top
top - 13:26:37 up 2:46, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31798.4 total, 31091.8 free, 817.4 used, 266.3 buff/cache
MiB Swap: 8192.0 total, 8192.0 free, 0.0 used. 30981.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 21172 12580 9612 S 0.0 0.0 0:00.28 systemd
2 root 20 0 2280 1304 1188 S 0.0 0.0 0:00.00 init-systemd(Ar
7 root 20 0 2280 4 0 S 0.0 0.0 0:00.00 init
38 root 20 0 66196 16716 15580 S 0.0 0.1 0:00.07 systemd-journal
73 root 20 0 30224 8732 7364 S 0.0 0.0 0:00.07 systemd-udevd
114 dbus 20 0 9172 4216 3468 S 0.0 0.0 0:00.01 dbus-broker-lau
115 dbus 20 0 4392 2668 2204 S 0.0 0.0 0:00.00 dbus-broker
116 root 20 0 17536 7896 6900 S 0.0 0.0 0:00.04 systemd-logind
124 root 20 0 9336 1480 1240 S 0.0 0.0 0:00.00 agetty
134 root 20 0 2284 116 0 S 0.0 0.0 0:00.00 SessionLeader
135 root 20 0 2300 120 0 S 0.0 0.0 0:00.14 Relay(136)
136 xiufeigo 20 0 7780 5072 4300 S 0.0 0.0 0:00.07 bash
137 root 20 0 7960 4824 4148 S 0.0 0.0 0:00.00 login
145 xiufeigo 20 0 20096 11036 9132 S 0.0 0.0 0:00.04 systemd
147 xiufeigo 20 0 22780 1748 0 S 0.0 0.0 0:00.00 (sd-pam)
156 xiufeigo 20 0 7644 4168 3732 S 0.0 0.0 0:00.00 bash
192 xiufeigo 20 0 12172 5464 3312 R 0.0 0.0 0:00.00 top这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率。需要注意的是 top 默认显示的是所有 CPU 的平均值,如果想查看单个核心的 CPU 使用率的话需要按下数字 1 。对 CPU 所在行的参数解读:
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
system(通常缩写为 sys 或 sy),代表内核态 CPU 时间。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。需要注意的是,top 并没有细分进程的用户态 CPU 和内核态 CPU.
2)pidstat
pidstat 是一个专门分析每个进程 CPU 使用情况的工具,输出内容包括:
用户态 CPU 使用率 (%usr)
内核态 CPU 使用率(%system)
运行虚拟机 CPU 使用率(%guest)
等待 CPU 使用率(%wait)
以及总的 CPU 使用率(%CPU)
最后的 Average 部分,还计算了多组数据的平均值。
# 每隔1秒输出一组数据,共输出 5 组
$ pidstat 1 5
Linux 3.10.0-1160.88.1.el7.x86_64 (custom-sep-10764dp38689843) 05/06/2024 _x86_64_ (4 CPU)
01:35:36 PM UID PID %usr %system %guest %CPU CPU Command
01:35:37 PM 978 1011 1.00 0.00 0.00 1.00 1 impalad
01:35:37 PM 0 2227 0.00 1.00 0.00 1.00 0 bash
01:35:37 PM 0 2472 1.00 0.00 0.00 1.00 2 barad_agent
01:35:37 PM 0 4040 0.00 1.00 0.00 1.00 1 YDService
01:35:37 PM 1001 13020 1.00 0.00 0.00 1.00 2 java
01:35:37 PM 1001 14495 1.00 0.00 0.00 1.00 3 mysqld
01:35:37 PM 1001 14952 0.00 1.00 0.00 1.00 2 pidstat
01:35:37 PM 985 17327 1.00 0.00 0.00 1.00 2 java
01:35:37 PM 985 17352 1.00 0.00 0.00 1.00 3 java
01:35:37 PM 0 17367 0.00 1.00 0.00 1.00 3 cmf-agent
01:35:37 PM 995 17478 1.00 0.00 0.00 1.00 1 java
01:35:37 PM 995 23363 1.00 1.00 0.00 2.00 1 java
01:35:37 PM 990 23683 0.00 1.00 0.00 1.00 1 java
01:35:37 PM 994 23685 1.00 0.00 0.00 1.00 1 kudu-tserver
01:35:37 PM 994 23730 3.00 2.00 0.00 5.00 1 kudu-tserver
01:35:37 PM 992 27564 1.00 0.00 0.00 1.00 1 java
01:35:37 PM 992 28917 1.00 0.00 0.00 1.00 2 java
01:35:37 PM 985 32384 0.00 1.00 0.00 1.00 0 java
......
Average: UID PID %usr %system %guest %CPU CPU Command
Average: 0 9 0.00 0.20 0.00 0.20 - rcu_sched
Average: 978 1011 0.80 0.40 0.00 1.20 - impalad
Average: 0 2412 0.00 0.20 0.00 0.20 - YDLive
Average: 0 2472 0.60 0.20 0.00 0.80 - barad_agent
Average: 0 4040 0.40 0.40 0.00 0.80 - YDService
Average: 0 5300 0.20 0.00 0.00 0.20 - nginx
Average: 1001 7742 0.20 0.00 0.00 0.20 - java
Average: 1001 13020 0.20 0.00 0.00 0.20 - java
Average: 1001 13293 0.00 0.20 0.00 0.20 - python3
Average: 1001 13317 0.20 0.20 0.00 0.40 - java
Average: 1001 13552 0.20 0.00 0.00 0.20 - java
Average: 1001 14495 0.20 0.00 0.00 0.20 - mysqld
Average: 1001 15393 0.20 0.60 0.00 0.80 - pidstat
Average: 0 16481 0.20 0.00 0.00 0.20 - python
Average: 985 17310 0.20 0.00 0.00 0.20 - java
Average: 985 17327 0.20 0.20 0.00 0.40 - java
Average: 985 17352 0.20 0.00 0.00 0.20 - java
Average: 985 17354 0.20 0.00 0.00 0.20 - java
Average: 0 17367 0.60 0.20 0.00 0.80 - cmf-agent
Average: 995 17478 0.80 0.00 0.00 0.80 - java
Average: 1001 17752 0.20 0.00 0.00 0.20 - zellij
Average: 1001 18142 0.00 0.20 0.00 0.20 - top
Average: 995 23363 0.80 0.80 0.00 1.60 - java
Average: 990 23683 0.20 0.20 0.00 0.40 - java
Average: 994 23685 0.20 0.20 0.00 0.40 - kudu-tserver
Average: 994 23687 0.20 0.00 0.00 0.20 - kudu-master
Average: 994 23730 2.99 1.80 0.00 4.79 - kudu-tserver
Average: 994 23745 0.20 0.00 0.00 0.20 - kudu-master
Average: 975 24509 0.60 0.00 0.00 0.60 - java
Average: 1001 26957 0.20 0.00 0.00 0.20 - java
Average: 992 27564 0.20 0.00 0.00 0.20 - java
Average: 992 28917 0.00 0.20 0.00 0.20 - java
Average: 985 32462 1.20 0.40 0.00 1.60 - java三、CPU 使用率过高怎么办
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进程。在找到对应进程后,可以通过 perf 来找出对应的函数。
1)perf top
perf top 是一个类似于 top 的工具,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
$ perf top
Samples: 17K of event 'cpu-clock', 4000 Hz, Event count (approx.): 2867343643 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
9.00% [kernel] [k] _raw_spin_unlock_irqrestore
6.04% [kernel] [k] finish_task_switch
2.82% [kernel] [k] find_busiest_group
2.42% [kernel] [k] __do_softirq
1.40% perf [.] __symbols__insert
0.98% [kernel] [k] system_call_after_swapgs
0.94% perf [.] rb_next
0.92% [kernel] [k] source_load
0.91% [kernel] [k] tick_nohz_idle_enter
0.88% [kernel] [k] eventfd_write
0.87% [kernel] [k] rcu_gp_kthread
0.79% libc-2.17.so [.] _int_malloc
0.74% [kernel] [k] load_balance
0.73% [kernel] [k] rcu_process_callbacks
0.69% [kernel] [k] __do_page_fault
0.63% libpython2.7.so.1.0 [.] PyEval_EvalFrameEx
0.58% [kernel] [k] __x2apic_send_IPI_mask
0.55% [kernel] [k] tick_nohz_idle_exit
0.55% libc-2.17.so [.] 0x00000000000ff0e7
0.48% kudu-tserver [.] operator new[]
0.47% [kernel] [k] find_next_bit
0.47% [kernel] [k] cpumask_next_and
0.45% [vdso] [.] __vdso_clock_gettime
0.44% [kernel] [k] __audit_syscall_exit
0.41% libstdc++.so.6.0.19 [.] std::string::find
0.41% [kernel] [k] copy_user_generic_string
0.40% perf [.] rust_is_mangled
0.40% [kernel] [k] update_group_power
0.39% perf [.] perf_evsel__parse_sample
0.38% [kernel] [k] queue_work_on输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 17K 个 CPU 时钟事件,而总事件数则为 2867343643。其中采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
# 常用参数:
-g:开启调用关系分析
-p:指定进程号2)perf record 和 perf report。
perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
$ perf record # 按Ctrl+C终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]
$ perf report # 展示类似于perf top的报告在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
四、wa(IO wait)很高该怎么办
分析 wa 一般使用 dstat,根据输出的 wal 列与disk/total 列做比较即可。
dstat 是一个多功能的资源监控工具,可以替代诸如 vmstat、iostat、netstat 和 ifstat 等工具。它能够实时提供 CPU、磁盘、网络和内存使用情况等系统资源统计数据。
1)基本用法
# 间隔 1s 输出 10 组数据
$ dstat [--interval] 1 [--count] 10
You did not select any stats, using -cdngy by default.
Color support is disabled, python-curses is not installed.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
9 3 88 0 0 0| 61k 1164k| 0 0 | 0 0 |9761 25k
2 2 96 0 0 0| 0 310k| 211k 212k| 0 0 | 13k 22k
5 1 93 0 0 0| 0 467k| 139k 309k| 0 0 | 12k 20k
1 1 98 0 0 0| 0 44k| 133k 126k| 0 0 | 12k 20k
9 4 87 0 0 0| 0 553k| 164k 156k| 0 0 | 16k 25k
11 5 84 0 0 0| 0 380k| 160k 172k| 0 0 | 17k 26k
12 4 84 0 0 0| 0 209k| 163k 149k| 0 0 | 15k 23k
12 6 81 0 0 0| 0 1496k| 169k 146k| 0 0 | 18k 26k
9 4 86 1 0 0| 0 632k| 131k 123k| 0 0 | 18k 27k
2 1 96 0 0 0| 0 588k| 128k 121k| 0 0 | 14k 24k
1 1 97 0 0 0| 0 768k| 133k 173k| 0 0 | 13k 22k2)CPU、磁盘和网络监控
$ dstat -cdng
Color support is disabled, python-curses is not installed.
----total-cpu-usage---- -dsk/total- -net/total- ---paging--
usr sys idl wai hiq siq| read writ| recv send| in out
9 3 88 0 0 0| 61k 1164k| 0 0 | 0 0
17 10 73 0 0 0| 0 470k| 173k 177k| 0 0
13 9 79 0 0 0| 0 2566k| 170k 142k| 0 0
12 9 79 0 0 0| 0 235k| 199k 155k| 0 0
13 8 78 0 0 0| 0 1029k| 140k 131k| 0 0
3 5 91 1 0 0| 0 482k| 127k 165k| 0 03)类似 top 的视图
$ dstat --top-cpu --top-io
Color support is disabled, python-curses is not installed.
-most-expensive- ----most-expensive----
cpu process | i/o process
kudu-tserver 0.9|main.py 2895k 106k
kudu-tserver 0.9|kudu-tserve 21k 3816B
kudu-tserver 0.9|barad_agent 26k 10k
etcd 0.9|bin/leader 97k 35k
java 3.2|bin/agent 1196k 3747B
kudu-tserver 0.8|bin/agent 956k 726B
kudu-tserver 0.8|main.py 4873k 195k
replica_serve1.2|main.py 13M 683k
kudu_tserver.2.1|main.py 13M 512k
zookeeper_ser2.2|main.py 15M 562k
main.py 1.0|main.py 17M 683k
impalad 5.4|main.py 5843k 941B4)内存使用情况:
$ dstat -m
Color support is disabled, python-curses is not installed.
------memory-usage-----
used buff cach free
29.3G 393M 29.0G 2472M
29.3G 393M 29.0G 2485M
29.3G 393M 29.0G 2490M五、系统的 CPU 使用率很高,但却找不到高 CPU 的应用
通过了 top,发现%Cpu(s)高达 80%,但是进程列表却没有占用高的程序,该如何排查呢?
1)经验法(顺序排查法)
使用 top 观察,整体 CPU 占用较高,但子进程无高占用
使用
pidstat 1,也没找到高占用进程发现有进程的 PID 一直在变化。正常有以下两种情况
第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了。
第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现。
使用
pstress查找一个进程的父进程,找到频繁启停的进程的父进程pstree | grep 进程名perf record -g记录性能事件,perf report查看性能报告找到父进程及对应代码,进行修复
2)execsnoop
execsnoop 就是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。
execsnoop 所用的 ftrace 是一种常用的动态追踪技术,一般用于分析 Linux 内核的运行时行为。
小结:
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源。
若 CPU 使用率大部分为 wa 占用,则可通过dstat 与pidstat、 strace 工具相结合,最后再使用 perf 等工具来排查引起性能问题的具体函数